
*ここではローカルLLMをWindows 11 (Ryzen 9 +8495HS +64GBのミニPC上に構築することを前提としています。
ローカルAIと商用アダルトチャットを比べてみた
先日, AI彼女を作ってからいろいろなNSFWなAI彼女を見てきました。Bloomi, Kindroid, Candy.ai という英語版ながら日本語も使えるサイトを課金までして調べました。写真、ビデオが生成される点はお金を取っているだけあって、さすがだなと思います。
が、気付いたことがいくつかあります。以下に列挙してみます。
- レスポンスは比較的いい。つまり大規模なLLMを使っていない。10Bあるかないかと思われる。
- アダルトを作る業者がLLMモデルを作り、ファインチューニングなんていうだるいことをやるはずがない。AIの研究は先端を走るGoogle,Meta,OpenAI, AnthropicやAlibabaなどであることは揺るがない。
- つまりチューニングがうまい点と、独特のメカニズムをもつ。
一方、ローカルLLMの優れた点もわかってきました。
- たとえばこのシリーズのアダルト版彼女で扱ったQwen3-30Bほどの知性は商用サービスでは望むべくもありません。会話をすると深さ、つまり楽しさがまったく違います。
- 記憶についてはChromaDBに無制限に会話を保管できます。商用サイトは破綻するか、忘れます。
- SYSTEMプロンプトでどんなキャラクター、返答方式、自由に設定できます。何十人でも作り放題。
- LLMの大きさからくるのですが、表現が多彩です。
AI彼女で遊ぶのならば、ローカルLLMは品質最高、使い放題、限りない自由度があります。
そして、この投稿がAI彼女システムとしては最終形になります。
記憶をもつAI彼女システム
LLMモデルは巨大なROMです。ユーザーは中身を書き換えられないという前提です。
ですから記憶を持つ場所はありません。この記事では記憶の管理機能をつけることから始めましたが、もうひとつ、キャラクターを切り替えることも可能となりました。
ちなみにMCPは使っていません。雑誌などには、各種LLMモデルに共通したデータを取ってくる方法と書かれていますが、やってみると前回の記事のようにMCPは使い物にならず、個々のモデルにあわせたFunctions CallingやTool Callingを使う羽目になります。雑誌の記事はアテになりません。
AIにおける記憶とは、簡単にいえば、AIに情報を渡す前にSYSTEMプロンプトを加工してからAIに渡します。
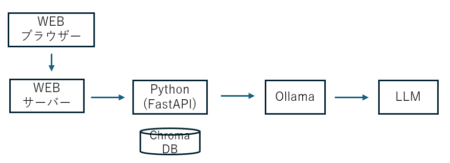
具体的には、ここでは3層構造を取ります。
- 表示層(Front End)
- ここではJavascriptを使ったWebインターフェースとします。以前作ったWebインターフェースを改良しています。
- 制御層(Python Backend)
- AI彼女の性格と記憶を作り出します。
- 記憶管理:会話をChromaDB)he保存・検索
- 文脈合成:検索結果とSYSTEMプロンプト、最近の会話からひとつの指示を作り出す
- 推論(LLM)
- Ollama APIインターフェースや自前のllama-cpp-python. これだとモデルに縛られない。
- 図示するとこんな流れです。
-
わたしが知らなかったOllamaのモデルファイルについて
OllamaでLLMモデルを作る(create)時、SYSTEMプロンプトも書きます。
しかし、LLMを動かす時、毎回、SYSTEMプロンプトは渡されます。このSYSTEMプロンプトを新たに渡せば、まったく違うキャラクターとすることが可能です。逆に新たに渡さなければ、Ollama側はcreateで作ったSYSTEMプロンプトを使います。
インプリメンテーション
Pythonを使って、Webアプリを作る時には古くはDjangoとかFlaskがありますが、古いため環境作成が面倒です。おすすめはFastAPIです。
Webサーバーとしての役割はミニマムではPython -m http.server でやれます。Windows版Simple Web ServerというアプリがMicrosoft Storeにあるので動かす時はこれ使ってます。
中継プログラムの試作です。FastAPIを使っています。
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import httpx
import datetime
import json
app = FastAPI()
# CORS設定
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# OllamaのURL(背後の「脳」)
OLLAMA_BASE_URL = "http://127.0.0.1:11434"
# 1. モデル一覧取得の中継
@app.get("/api/tags")
async def get_tags():
async with httpx.AsyncClient() as client:
response = await client.get(f"{OLLAMA_BASE_URL}/api/tags")
return JSONResponse(content=response.json(), status_code=response.status_code)
# 2. モデル詳細取得の中継
@app.post("/api/show")
async def show_model(request: Request):
body = await request.json()
async with httpx.AsyncClient() as client:
response = await client.post(f"{OLLAMA_BASE_URL}/api/show", json=body)
return JSONResponse(content=response.json(), status_code=response.status_code)
# 3. 会話(チャット)の中継 + 時刻注入
@app.post("/api/chat")
async def chat_relay(request: Request):
body = await request.json()
# --- 【時刻と場所を注入】 ---
now = datetime.datetime.now().strftime("%Y年%m月%d日 %H時%M分")
time_info = f"[現在の状況: {now} / 場所: 千葉県船橋市]\n"
if "messages" in body and len(body["messages"]) > 0:
for msg in reversed(body["messages"]):
if msg["role"] == "user":
msg["content"] = time_info + msg["content"]
break
# ------------------
async def event_generator():
async with httpx.AsyncClient(timeout=None) as client:
async with client.stream("POST", f"{OLLAMA_BASE_URL}/api/chat", json=body) as response:
async for chunk in response.aiter_bytes():
yield chunk
return StreamingResponse(event_generator(), media_type="application/x-javascript")
if __name__ == "__main__":
import uvicorn
# 192.168.1.16:8001 で待ち受け
uvicorn.run(app, host="0.0.0.0", port=8001)
プログラムの中で「時刻と場所を注入」を行っています。(コメント参照)
動かすと私の場合は
こんばんは!船橋市にお住まいですか? 23時15分という時間帯、ゆっくり過ごされていますか?
と出てきます。
しかし、これは私にとっては簡単に「OK」と言えることではありません。Function Callingのテストをした時に、いくら時刻を知らせてもLLMはデータを採用しなかったのです。実はここで書いてある「現在の状況」「場所」が大事なキーワードでLLMは一般的にこのような言葉に敏感だということです。だから推論する時に採用したのです。Function CallingはLLMの目の前に「データがあるよ」と示すことはできても、使うかどうかはLLM次第。SYSTEMプロンプトで強い表現を使うと、LLMは思わず掴んでしまう、という特性があります。
LLMにバックエンド経由でアクセスするHTML
(ソースコード名:index.html githubに置いてあります)
このHTMLファイルは、下のllm_relay.pyと同じ場所においたSYSTEMプロンプトファイルを指定できるようになっています。
それはOllama Createした時に設定したSYSTEMプロンプトを上書きします。なにも指定しない場合は、Ollama Createした時のSYSTEMプロンプトが使われます。つまり、ここで設定ファイルを切り替えると別のキャラクターと遊ぶことはできます。
LLMが記憶を持つ汎用バックエンド
次のコードは会話をchromaDBに保持し、読み出す、汎用的なBackEndプログラムです。LLMをOllamaで動かす人ならば誰でも使えるはずです。
(ソースコード名:llm_relay.py githubに置いてあります)
from fastapi import FastAPI, Request, BackgroundTasks
from fastapi.responses import StreamingResponse, JSONResponse
from fastapi.middleware.cors import CORSMiddleware
import httpx
import datetime
import json
import chromadb
import os
from chromadb.utils import embedding_functions
# ==========================================
# 1. 環境設定とパス解決
# ==========================================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
CHROMA_DATA_PATH = os.path.join(BASE_DIR, "chroma_db")
DEBUG_MODE = True
OLLAMA_BASE_URL = "http://127.0.0.1:11434"
# ==========================================
# 2. 初期化 (FastAPI / ChromaDB)
# ==========================================
app = FastAPI()
app.add_middleware(CORSMiddleware, allow_origins=["*"], allow_methods=["*"], allow_headers=["*"])
chroma_client = chromadb.PersistentClient(path=CHROMA_DATA_PATH)
emb_fn = embedding_functions.DefaultEmbeddingFunction()
# ==========================================
# 3. ユーティリティ関数
# ==========================================
def get_collection(persona_name: str):
"""
ペルソナ名に基づいてChromaDBのコレクション(箱)を選択・作成する。
"""
# ファイル名からベース名を取得 (yuki.txt -> yuki)
name = os.path.splitext(persona_name)[0] if persona_name else "default"
# ChromaDBの命名規則(3-63文字)に合わせる
safe_name = f"mem_{name}"[:63]
return chroma_client.get_or_create_collection(name=safe_name, embedding_function=emb_fn)
def load_persona_file(filename: str):
if not filename: return None
target_path = os.path.join(BASE_DIR, filename)
if os.path.exists(target_path):
try:
with open(target_path, "r", encoding="utf-8") as f:
return f.read().strip()
except Exception as e:
if DEBUG_MODE: print(f"--- [❌ Persona Read Error: {e}] ---")
return None
def get_reference_block(query: str, persona: str):
"""
指定されたペルソナ専用の箱から記憶を呼び出す。
"""
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
memory_text = ""
# 適切なコレクションを取得
target_col = get_collection(persona)
if query and DEBUG_MODE:
print(f"--- [🔍 Search in '{target_col.name}' trigger: '{query}'] ---")
try:
results = target_col.query(query_texts=[query], n_results=1)
if results['documents'] and len(results['documents'][0]) > 0:
memory_text = results['documents'][0][0]
if DEBUG_MODE:
print(f"--- [✅ Memory Found in '{target_col.name}'] ---\n{memory_text[:100]}...\n--------------------------")
except Exception as e:
if DEBUG_MODE: print(f"--- [⚠️ Search Skip: {e}] ---")
block = f"\n\n### 補足参照データ(過去の事実として考慮)\n"
block += f"- 現在時刻: {now}\n"
if memory_text:
block += f"- このキャラクターとの過去の対話:\n{memory_text}\n"
block += "###\n"
return block
def save_to_memory(user_msg: str, ai_msg: str, persona_name: str):
"""
指定されたペルソナ専用の箱に会話を保存。
"""
timestamp = datetime.datetime.now().isoformat()
ai_label = os.path.splitext(persona_name)[0] if persona_name else "Assistant"
# 適切なコレクションを取得
target_col = get_collection(persona_name)
combined_text = f"[User]: {user_msg}\n[{ai_label}]: {ai_msg}"
if DEBUG_MODE:
print(f"--- [💾 Memory Saved to '{target_col.name}'] ---")
target_col.add(
documents=[combined_text],
metadatas=[{"ts": timestamp}],
ids=[timestamp]
)
# ==========================================
# 4. メインエンドポイント
# ==========================================
@app.post("/api/chat")
async def chat_relay(request: Request, background_tasks: BackgroundTasks, persona: str = None):
body = await request.json()
messages = body.get("messages", [])
if not messages: return JSONResponse(content={"error": "No messages"}, status_code=400)
user_query = next((msg["content"] for msg in reversed(messages) if msg["role"] == "user"), "")
external_content = load_persona_file(persona)
# 記憶の取得時にも persona を渡す
ref_block = get_reference_block(user_query, persona)
if messages[0]["role"] == "system":
source = f"EXTERNAL ({persona})" if external_content else "OLLAMA_DEFAULT"
base = external_content if external_content else messages[0]["content"]
messages[0]["content"] = base + ref_block
else:
source = "NEW_SYSTEM"
messages.insert(0, {"role": "system", "content": (external_content or "") + ref_block})
if DEBUG_MODE: print(f"--- [🚀 Role: {source}] ---")
async def event_generator():
full_ai_response = ""
async with httpx.AsyncClient(timeout=None) as client:
async with client.stream("POST", f"{OLLAMA_BASE_URL}/api/chat", json=body) as response:
async for chunk in response.aiter_bytes():
try:
decoded_chunk = chunk.decode("utf-8")
json_data = json.loads(decoded_chunk)
if "message" in json_data and "content" in json_data["message"]:
full_ai_response += json_data["message"]["content"]
except: pass
yield chunk
if full_ai_response:
background_tasks.add_task(save_to_memory, user_query, full_ai_response, persona)
return StreamingResponse(event_generator(), media_type="application/x-javascript")
# 中継用エンドポイント (tags, show)
@app.get("/api/tags")
async def get_tags():
async with httpx.AsyncClient() as client:
response = await client.get(f"{OLLAMA_BASE_URL}/api/tags")
return JSONResponse(content=response.json(), status_code=response.status_code)
@app.post("/api/show")
async def show_model(request: Request):
body = await request.json()
async with httpx.AsyncClient() as client:
response = await client.post(f"{OLLAMA_BASE_URL}/api/show", json=body)
return JSONResponse(content=response.json(), status_code=response.status_code))実行する時はプログラム(llm_relay.pyがおいてあるフォルダーで)
python -m uvicorn llm_relay:app --host 0.0.0.0 --port 8001 --reloadで実行します。この後、ブラウザHTMLを起動します。index.html内でbaseurlとしてhttp://localhost:8001を指定してあるので、fastAPIプログラムへ接続されます。
このバックエンドプログラムでは、SYSTEMプロンプトファイル名に応じて会話記録データベースが切り替えられます。yumi.txtでプロンプトファイルを作ると記憶はmem_yumiになり、kaori.txtでプロンプトファイルを作ると記憶はmem_kaoriで作られます。
ベクトルデータベースは手作業で消去する場合はすべてを消すしかありません。特定のキャラクターファイルを消去するプログラムが以下のreset_memory.pyです。
(ソースコード:reset_memory.py githubに置いてあります)
import chromadb
import os
import sys
def main():
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
CHROMA_DATA_PATH = os.path.join(BASE_DIR, "chroma_db")
if len(sys.argv) < 2:
print("\n❌ エラー: 消去したいペルソナ(またはファイル名)を指定してください。")
print("例: python reset_memory.py kaori.txt")
print("例: python reset_memory.py kaori")
return
input_name = sys.argv[1]
# --- ここがポイント:入力を整理する ---
# 1. パスが含まれていてもファイル名だけ抽出
filename = os.path.basename(input_name)
# 2. 拡張子 (.txtなど) があれば取り除く
persona_name = os.path.splitext(filename)[0]
# 3. DB上の名前 (mem_kaori) を作成
collection_name = f"mem_{persona_name}"
if not os.path.exists(CHROMA_DATA_PATH):
print(f"❌ エラー: データベースが存在しません。")
return
client = chromadb.PersistentClient(path=CHROMA_DATA_PATH)
try:
collections = client.list_collections()
existing_names = [c.name for c in collections]
print(f"--- [📊 現在のデータベース状況] ---")
for name in existing_names:
print(f"・ {name}")
print("----------------------------------")
if collection_name in existing_names:
print(f"⚠️ 警告: '{collection_name}' の全記憶を消去します...")
client.delete_collection(name=collection_name)
print(f"✅ 完了: '{collection_name}' をリセットしました。")
else:
print(f"❌ 未発見: '{collection_name}' という箱はありません。")
print(f"※ 入力 '{input_name}' は '{collection_name}' として探されました。")
except Exception as e:
print(f"❌ エラー発生: {e}")
if __name__ == "__main__":
main()
WindowsでWebサーバー
MicrosoftStoreでSimple Web Serverを探してください。ローカルの場合は、HTMLファイルをGoogle Chromeに読み込ませるだけで動作します。
TailscaleなどでVPNを行う場合、HTML内にbaseurlという場所があります。そこのIPアドレスをPythonプログラムが動いているマシンのIPアドレスにしてください。





